Šiuolaikinė išvestinių finansinių priemonių įkainojimo technika remiasi sudėtingiausiais matematiniais metodais, taikomais finansuose. O pritaikymo sričių yra labai įvairių – pavyzdžiui, panagrinėkime opcionus bei kam juose reikia taikyti įvairius matematinius metodus.
Pasirinkimo sandorio (opciono) sąvoka turi gilias istorines šaknis. Antikos laikais romėnai, graikai ir finikiečiai prekiavo išvykstančių iš vietinių uostų laivų krovinių opcionais. Finansinių aktyvų atveju opcionas bendruoju atveju apibrėžiamas kaip sandoris tarp dviejų šalių, kurių viena turi teisę, bet ne įsipareigojimą pirkti ( pirkimo opcionas) ar parduoti ( pardavimo opcionas) pagrindinį aktyvą, pvz. akcijas tam tikru laiku už iš anksto nustatytą kainą. Tuo tarpu antroji pusė pareikalavus pirmajai privalo įvykdyti sandorio sąlygas. Opciono pirkėjas turėdamas teisę be įsipareigojimo įgyja tam tikrą vertę, todėl opciono turėtojas turi sumokėti už šią teisę kažką pirkti ar parduoti. Kaina, kuri sumokama už opcioną vadinama premija. Jei opciono pabaigoje akcijos kaina pakyla aukščiau sutartos kainos, tai pirkimo opciono savininkas perka akciją už žemesnę kainą ir ją pardavęs rinkoje už aukštesnę kainą uždirba pelno. Jei akcijos kaina nepakyla aukščiau sutartos kainos, tai opcionas nerealizuojamas ir opciono turėtojas patiria nuostolį, lygų opciono pirkimo kainai. Matematinė problema yra teisingai nustatyti opciono kainą, kuria būtų patenkintos abi sandorio pusės ir tuo pačiu nebūtų pažeista finansų rinkos pusiausvyra. Svarbiausias uždavinys yra prognozuoti pagrindinio aktyvo atsitiktinės kainos dinamiką arba nustatyti aktyvo kainos skirstinį opciono realizavimo metu. Tam yra kuriami matematiniai modeliai.
Mintis taikyti matematinius metodus prognozuojant ateitį jau kilo dviems XVII a. prancūzų matematikams Blaise Pascal ir Pierre De Fermat (žinomas kaip paskutinės Ferma teoremos autorius). Šie mokslininkai susirašinėdami 1654 m. apskaičiavo žaidimo, metant du lošimo kauliukus fiksuotą skaičių kartų, visų galimų baigčių tikimybes.
Tarkime Jonas ir Petras žaidžia azartinį žaidimą, kuris iš jų laimės penkis kartus metant du lošimo kauliukus? Po trijų metimų Jonas pirmauja 2:1. Kokia teisingą sumą jus turite statyti lažinantis, kad laimės Petras, jei aš moku 100Lt jam laimėjus? Pascal ir Fermat parodė kaip rasti teisingą atsakymą. Pagal juos tikimybė, kad Petras laimės lygi 0,25. Šiuo atveju, jei aš sutinku, kad statytumėte 25Lt , tai mano siūloma suma yra visai teisingai įvertinta. Statoma suma mažesnė už 25lt yra naudingesnė jums, o suma didesnė negu 25Lt yra palankesnė man. Matematiniai modeliai nepanaikina rizikos, o tik teisingai nustato kainą su kuria abi besilažinančios pusės yra vienodose sąlygose.
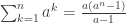
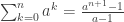
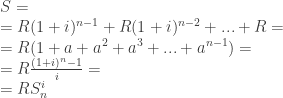

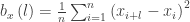


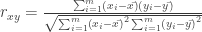
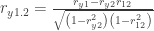


 – koreliacijos koeficientai;
– koreliacijos koeficientai;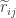 -dalinės koreliacijos koeficientai.
-dalinės koreliacijos koeficientai.